
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- #annotation
- #선형
- #activation function
- #Linux
- pytorch
- Linux
- #pytorch
- #Jetson nano
- #비선형
- #object detection
- #landmark
- #torchvision
- #gpu training
- #Anaconda
- Today
- Total
Wooks_learning
End-to-End Object Detection with Transformers [논문 리뷰] 본문
해당 논문은 ECCV 2020에 발표된 논문으로, Facebook AI Research팀이 발표한 논문이다.
ViT 보다 더 빠르게 vision task에서 transformer 구조를 사용하여 object detection task를 풀어낸 논문으로,
transformer가 vision task에서 유의미한 성능을 거두고, 높은 잠재력이 있다는 것을 알려준 논문으로 대표된다.
해당 글은 아래와 같은 순서로 정리한다.
- Abstract
- Architecture
- Backbone Network
- Transformer Encoder
- Transformer Decoder
- loss function
- Experiments
- Faster R-CNN VS DETR
- Encoder Visualization
- Decoder Visualization
- Conclusion
1. Abstract
기존의 Object detection은 heuristic한 방법(NMS, Anchor box)과 같은 방법을 사용하여 간접적으로 해결하였다.
따라서 Direct set prediction으로 Object detection을 직접적인 방법으로 해결할 수 있다고 한다. Set(집합)이 가지는 특징인 중복이 없고, 순서에 상관이 없다라는 특성과 Transformer 구조의 permutation invariant한 성질이 Object detection을 해결하는데에 도움을 준다고 한다.

그와 더불어, Hungarian Algorithm을 사용해 NMS를 사용하지 않아도, 각각의 instance에 대한 Bounding box의 중복제거를 해줄 수 있다. 따라서 End-to-End로 학습이 가능하고, NMS와 같은 heuristic한 방식을 사용하지 않고 다른 detector(본 논문에선 Faster R-CNN과 비교)와 비교했을 때 간소화된 pipeline으로 competitive한 성능을 달성함.

2. Architecture

전체적으로 살펴보면, 1) backbone 네트워크를 거쳐 이미지의 feature map을 뽑아내고, 거기에 positional encoding을 더해준다. 해당 작업을 거친 후 2) encoder구조에 input으로 사용하고 encoder에서 얻은 attention과 3) decoder의 object query의 attention을 통해 최종적으로 FFN을 통과하여 output을 출력하는 구조로 되어있다.
2-1) Backbone Network
Backbone으로 ResNet을 사용하였고, 과정은 아래와 같다.
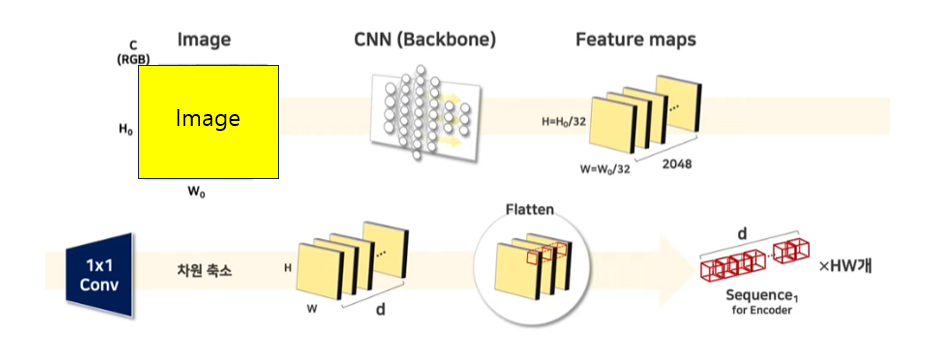
feature map을 뽑아 해당 feature map에 1x1 conv를 적용하여 d차원(해당 논문에선 256)으로 차원을 축소해 준다.
그 후 d 차원으로 축소된 feature map의 각 픽셀끼리 묶어 길이가 d인 token을 HW개로 만들어 준다. 각각의 토큰에 positional encoding을 더해주어 transformer encoder의 input으로 사용할 수 있도록 만들어 줌.
2-2) Transformer Encoder

해당 파트에선 feature map의 각 픽셀에 대해 attention을 학습하게 된다. 즉, 각각의 feature map pixel들이 Query, Key, Value가 되어 픽셀간의 attention을 구하게 되고, 그로 인해 object의 대략적인 위치와 관계를 학습하게 된다고 볼 수 있다. 해당 부분은 Experiment에서 시각화 자료를 통해 보면 참고가 될 것 같다.
2-3) Transformer Decoder

Decoder의 input인 object query가 Query가 되고, Encoder의 output이 Key가 되어 각각의 object query들이 어떠한 object를 찾을 수 있는지 학습 한다. 여기서 object query란 고정된 출력을 위한 빈 그릇이라고 생각하면 되는데(실제 논문에서 slot이라고 표현), 본 논문에서는 100개의 output 즉 Decoder의 입력으로 사용하는 object query의 개수가 100개이고, 해당 object query들이 모두 (class, bbox) 혹은 (No object, 0)를 output으로 뱉게 된다.
3. loss function
loss function은 2가지 step으로 구성된다.
1) optimal한 matching 찾기(sigma hat)
2) 해당 matching을 통한 loss 구성

위의 수식을 한 줄로 표현하면 L_match가 최소가 되는 matching 이라고 표현할 수 있다. 즉 optimal한 매칭을 찾는것이 위 수식의 역할인데, L_match를 살펴보면 일반적인 object detection에서 loss를 구성하는 것과 비슷하게 되어있다. class에 대한 cost는 확률을 그대로 사용하였고, 당연하게도 확률이 높을수록 cost가 높아질 것이기 때문에 확률에 대한 cost에 음수를 취해 주었고, box에 대한 cost는 GIoU와 L1 loss를 linear combination하여 box에 대한 cost를 정의하였다. box에 대한 cost는 아래 수식으로 정의 된다.

해당 매칭 cost를 기반으로 최적의 매칭을 찾고(hungarian algorithm으로), 최적의 매칭을 통해 아래와 같은 loss를 구성한다.
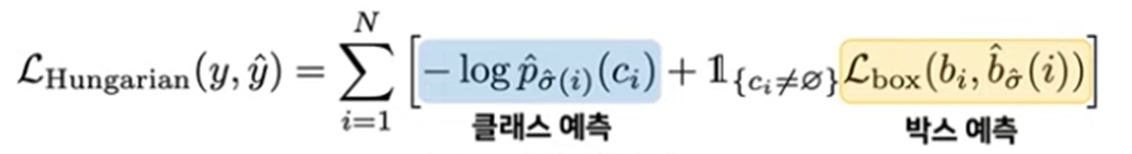
여기서 주의할점은 첫번째 step에서 hungarian algorithm으로 optimal한 matching을 찾는 것은 미분과는 상관이 없다. 즉, 학습을 통해 업데이트 되는 것이 아닌, 출력된 output을 통해 알고리즘적으로 최적의 matching을 찾아준다는 것을 유념해야 한다. 여기서 첫번째 step의 hungarian algorithm이 NMS를 대체했다고 볼 수 있다.
그래서 아래 그림과 같이 학습 되도록 만들어주는 loss로 생각하면 된다.

4. Experiment
4-1) Faster R-CNN VS DETR

위의 표는 Faster R-CNN과의 비교를 나타내는데, 해당 실험에서 자세히 살펴 볼 점은 AP_L(large object에 대한 AP Score)과, AP_S(small object에 대한 AP Score)로 생각되었다.
기존의 detector와 비교했을 때 AP_L에서 굉장히 높은 성능을 기록하고 있다. 이것이 의미하는 것은 기존의 CNN과 다른 heuristic한 방법을 사용한 detector와 비교했을 때 더 높은 성능을 가졌다는 것보다, transformer를 vision에서 사용 했을 때에도 충분히 좋은 결과를 가질 수 있다. 즉, vision에서 transformer의 잠재성을 확인해주는 실험이라고 생각하였다.
AP_S의 경우 Faster R-CNN이 조금 더 높은 성능을 가졌는데, 해당 논문에선 후속 논문이 해결해야할 점이라고 풀어내고 있다. 그리고 원래 Object detection task가 small object에 대해서 성능이 많이 떨어지는 경향이 있다고 한다. 왜 그런지 생각해보니 layer를 거치며 feature map을 뽑아내었을 때, 작은 object에 대한 정보가 소실되는 것이 원인일 것 이라고 생각하였다. 찾아보니 이를 해결하기 위해 Feature Pyramid를 이용하여 DETR을 적용했더니 해당 단점이 보완되었더라 하는 논문이 있었다(Deformable DETR이라고 검색하면 나옴).
4-2) Encoder Visualization

해당 실험의 경우 transformer의 Encoder layer에서 출력한 결과인데, 각각의 pixel에 대해 attention을 찍어보았을 때 어떤 pixel과 연관이 있는지를 시각화한 실험이다. 해당 실험에서 알 수 있는 부분은 Encoder에서 각각의 object instance끼리 attention이 잘 되는 것을 확인할 수 있다. 따라서 Decoder에서 조금 더 쉽게 bounding box를 쳐줄 수 있도록 하는 것이 Encoder의 역할이라고 생각하면 될 것 같다.
4-3) Decoder Visualization

해당 실험은 Decoder의 attention을 visualization 해주었는데, 해당 실험에서 알 수 있는 것은 각각의 object instance의 말단 부분 즉 가장자리에 attention이 되어있는 것을 확인할 수 있다. Decoder가 말단에 attention을 가하게 되면, FFN에서 매우 쉽게 bounding box를 쳐줄 수 있게 될 것이다.
즉, Encoder에서는 물체의 관계, 위치를 학습하고, Decoder에서는 bounding box를 잘 쳐줄 수 있도록 말단에 대한 정보를 학습한다고 보면 된다.
5. Conclusion
최종적으로 정리하면, 기존의 Detector들이 heuristic하게 간접적으로 접근하여 Object detection 문제를 해결한 것을 DETR이라는 모델과 Hungarian algorithm을 통한 loss 구성을 통해 Direct set prediction으로 해결하였다. 또한, 해당 논문을 통해 vision 분야에서 transformer의 잠재성을 확인하였다.
'딥러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] YOLOv10 Real-Time End-to-End Object Detection_1부 (0) | 2024.12.17 |
|---|---|
| [논문리뷰] Segment Anything (4) | 2024.10.07 |
| [논문리뷰] UNIVERSAL FEW-SHOT LEARNING OF DENSE PREDICTION TASKS WITH VISUAL TOKEN MATCHING (0) | 2023.09.10 |
| [논문리뷰] Zero shot text-to-image generation (0) | 2023.09.06 |



