
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- #선형
- #Anaconda
- #비선형
- #landmark
- #torchvision
- Linux
- #gpu training
- #activation function
- #Linux
- #pytorch
- pytorch
- #Jetson nano
- #annotation
- #object detection
- Today
- Total
Wooks_learning
[논문리뷰] UNIVERSAL FEW-SHOT LEARNING OF DENSE PREDICTION TASKS WITH VISUAL TOKEN MATCHING 본문
[논문리뷰] UNIVERSAL FEW-SHOT LEARNING OF DENSE PREDICTION TASKS WITH VISUAL TOKEN MATCHING
Wooks_ 2023. 9. 10. 13:26이번 글은 dense prediction task를 few-shot learning을 통해 성공적으로 학습한 논문에 대해 소개하려고 한다.
글의 순서는 다음과 같다.
1. Abstract
2. Introduction
3. Method
- Data 구성
- Image encoder
- Label encoder
- Matching module
- Label decoder
- Meta training loss
실험에 관한 내용은 발표자료에 그림으로 첨부하여 따로 정리하진 않겠다.
1. Abstract

해당 논문은 dense prediction task를 푸는 논문인데, 일단 dense prediction 자체가 생소할 수 있다.
여기서 dense prediction이란 input image를 주었을 때 각 픽셀마다의 예측값을 뱉어내는 task를 dense prediction이라고 한다. 예를 들어, segmentation, depth estimation처럼 각 픽셀별로 어떠한 class 혹은 continuous한 값을 예측하는 task라고 할 수 있을것 같다. 하지만 이렇게 픽셀별로 값을 예측하기 위해선 각 픽셀마다 label을 달아줘야 하는데, 해당 작업이 cost가 굉장히 많이 든다고 할 수 있다. 따라서 풍부한 데이터를 수집하려고 해도, labeling cost의 문제가 항상 걸림돌로 작용한다고 한다.
이를 해결하기 위해서 해당 논문에선 few-shot learning을 이용하여 적은 데이터로도 모델의 parameter를 새로운 도메인에 adaptation 시킬 수 있는 것이 가장 큰 contribution이라고 할 수 있다.
2. Introduction
dense prediction을 효율적으로 풀기위한 논문들은 해당 논문 이전에 상당 부분 존재했다.

그림 2에서 보는 것처럼 각각의 task에 대해 전이 학습을 진행하여 다양한 dense prediction task를 해결하려고 했지만, 해당 논문 같은 경우에도 여전히 학습을 위한 labeling cost가 많이 드는 단점이 존재한다.
그래서 사람들은 few-shot learning을 해당 task에 접목하기 시작하였는데, 존재하는 few-shot learning들은 task specific하게 동작하기 때문에 특정 task의 사전 지식을 dense prediction task로 일반화하는데 적합하지 않다.
따라서, 본 논문에서는 통합된 하나의 구조를 통해 다양한 task를 수행할 수 있고, unseen task에 유연하게 적응하여 보지 못한 task에 대해서도 잘 수행할 수 있는 VTM 구조를 제안한다.
3. Method

그림 3.을 참고하면 해당 구조가 상당히 복잡해 보일 수 있는데, 설명하기 쉽도록 각 모듈에 대해서 분할하여 설명하고자 한다.
3.1 Input data configuration
해당 논문은 few-shot learning을 이용하기 때문에 input data가 어떻게 구성되는지 잘 알아놓아야 할 필요가 있다.

일단 각각의 task별로 데이터들을 구성한 후, 각 task에 대한 데이터 안에서 query image와 support image set을 구성한다. 꼭 알고 넘어가야 할 것은 query image는 image, label 각각 한 장으로 이루어져있고, support image set은 여러 장의 image와 label 쌍으로 이루어져 있다.
3.2 Image encoder

본 논문에서 image encoder는 ViT 구조를 채택하였는데, 해당 구조를 통해 input image의 각 토큰에 대한 representation을 잘 추출할 수 있도록 학습하게 된다. Image encoder의 경우 task specific한 parameter를 사용하여 task가 sampling 될 때마다 각 task에 맞는 parameter를 학습하게되는 방법을 채택하고 있다. 정리하자면 모델 구조는 동일하지만 task specific한 parameter를 사용하여 task에 알맞은 parameter를 학습하는 것이 image encoder의 목적이다.
3.3 Label encoder

Label encoder의 경우 Image encoder와 동일한 ViT 구조를 사용하지만, image encoder와는 다르게 하나의 parameter를 사용하여 모든 task에 대해 업데이트 된다. 이렇게 하는 의미를 생각해보면 본 논문에서는 dense prediction이라는 여러가지의 task를 수행하게 되는데 여기서 중요한 것이 label에 대한 정보를 잘 추출해서 어딘가로 전달해야 하는 목적을 지닌 모듈이다. 즉, task에 general한 지식들을 학습하기 위해서 하나의 parameter만 가지고 모든 task를 학습하는 목적이라고 할 수 있다.
3.4 Matching module

해당 부분이 사실 논문에서 제안한 구조의 핵심적인 모듈이라고 할 수 있다. 해당 모듈의 경우 Image encoder를 통해 뽑은 query image와 support image set의 token representation의 attention을 구하는 모듈이라고 간단하게 이야기 할 수 있다.

수식을 천천히 뜯어보면, 굉장히 이해하기 쉬울 것으로 생각이 든다. 수식이 의미하는 것은 우리가 query에 대한 label token을 예측할 것인데, 해당 예측을 하기 위해서 예측할 부분과 동일한 위치의 query image token을 query로 사용하고, support image의 모든 token을 key값으로 사용하여 attention을 구하게 된다. 그 후 support label의 모든 token을 value값으로 사용하여 앞에서 구한 attention 값에 곱해주고 이를 모두 합하여 최종적인 attention score를 구해 query label token을 예측하는 방식을 채택한다.
조금 더 단순하게 이야기하면 1번째 label token을 예측하기 위해서 1번째 query image token을 query로 사용하여 모든 support image와의 관계(attention)를 파악하고, support image의 token들을 곱하여 또 한 번 관계를 보게 됨으로써 query image token과 가장 유사한 label token을 매칭해주는 형태라고 할 수 있다.
3.5 Label decoder

이제 query label의 token을 모두 예측했다면, 해당 token 정보를 이용하여 원본 형태의 label로 복원하는 과정을 거치면 짠하고 label image가 나오게 되는 것인데, 간단하게 각 계층에서 나온 query label token들을 upsampling하는 과정을 거쳐 점진적으로 원본 label의 크기로 복원시키는 구조를 가지고 있다. 당연하게도 hierarchical한 구조를 이용하면 multi-scale feature를 얻어 이미지의 표현을 풍부하게 할 수 있다는 이점을 가지기 때문에 차용했다고 할 수 있다.
3.6 Meta training loss
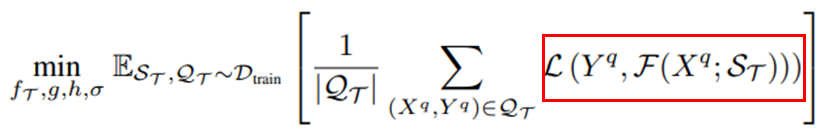
loss function은 굉장히 간단한 형태를 띄고있다. 각각 task에 대응되는 loss를 사용하게 되는데, 만약 segmentation task가 sampling 되었다면 query label과 predict label간의 cross entropy를 이용하는 방식을 사용한다. 또한 학습 과정에서 task-specific model의 bias parameter만을 업데이트하는 방식을 적용하였다. 어찌보면 학습이 잘 안 될 수 있지 않느냐라고 할 수 있지만, 해당 논문에서 제안한 방법론은 10장 정도의 image set을 support set으로 구성하게 되는데, support set에 over-fitting되지 않도록 방지하기 위해서 이러한 방식을 적용했다고 이야기한다.
이렇게 VTM 논문에 대해 살펴보았는데, 논문을 한 줄로 정리하자면 다양한 dense prediction task를 해결하기 위해 few-shot learning 방법론을 채택하였고 해당 과정에서 support label token을 잘 매칭해주는 방법론을 사용하여 SOTA model과 버금가는 성능을 얻어낼 수 있도록 한 것이 본 논문이 가지는 contribution이라고 생각되고, best paper를 받은 이유이지 않을까 생각이 든다.
'딥러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] YOLOv10 Real-Time End-to-End Object Detection_1부 (0) | 2024.12.17 |
|---|---|
| [논문리뷰] Segment Anything (4) | 2024.10.07 |
| [논문리뷰] Zero shot text-to-image generation (0) | 2023.09.06 |
| End-to-End Object Detection with Transformers [논문 리뷰] (0) | 2022.04.23 |



